Mapped UTF-8 → UTF-16 range lookups FTW
I’m writing a little OS X app which among other things highlight source code. To avoid re-inventing the wheel I’m using GNU Source-highlight1 to tokenize the input data. However, GNU Source-highlight only accept UTF-8 and Cocoa strings are UTF-16 so conversion is needed, which can be quite expensive.
My first implementation did something like this when an editing occurred and highlighting was performed:
- Get the (UTF-16) range of the modified substring (using various algorithms, not covered here)
- Convert the UTF-16 substring to a UTF-8 std::string representation
- Feed the tokenizer with the UTF-8 string
- When the tokenizer returns a token range, convert that range into a UTF-16 range (but only if the original UTF-16 length differs from the UTF-8 length, i.e. is a multibyte string)
Highlighting the source of http://hunch.se/stuff/ took a blazing 10 seconds when compiled with optimizations and auto-vectorization. Not even near OK.

Any programmer – mathematician or not – realize the high complexity of this algorithm. For each time we find a new token, iterate over the UTF-8 part of that edit and build a new range by considering UTF-8 bytes. A few simple optimizations (like avoiding repeated constant calculations) brought the time down to about 3.5 seconds for the same test case.
So I went to the theatre to see a play with a friend and clear my head. This morning I realized what I already knew but didn’t want to accept: I need a way to lower the complexity of the algorithm. Hmm, an index lookup table from UTF-8 to UTF-16 is probably the way to go.
After about 2 hours worth of googling, reading the ICU API, scrubbing Apple dev docs and almost desperately querying Codesearch I gave up and rolled my own implementation. For my use case, the result was a 14x real speed increase – the same test which earlier took 10 seconds now only took 0.7 seconds (which given the particular test case is good). Note that most of the 700 ms is spent on waiting for stupid kernel-calling locks, only ~250 ms worth of user+system cycles is actually used.
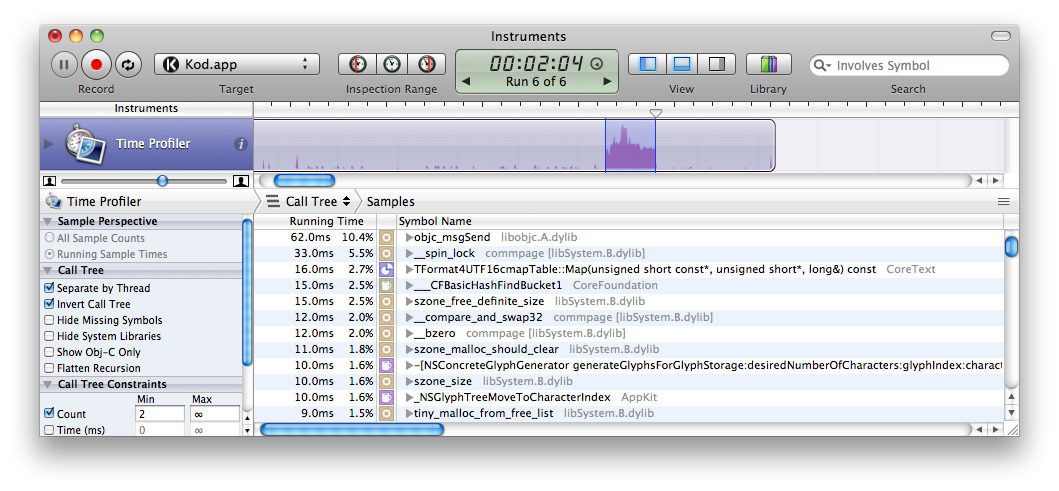
What I did was to convert UTF-16 into UTF-8 and build a look-up table at the same time. Now what takes time is the damn kernel-calling spin lock which is used by the Cocoa NSView hierarchy and boost (used by GNU Source-highlight for regexp). Don’t mind the “objc_msgSend” in the Instrument screenshot above as it represents the sum of Objective-C overhead for all cocoa calls.
I’m open-sourcing my solution under an MIT license:
https://gist.github.com/716794
Synopsis of HUTF8MappedUTF16String
(See actual source for details)
class HUTF8MappedUTF16String {
public:
HUTF8MappedUTF16String(unichar *u16buf=NULL, size_t u16len=0);
~HUTF8MappedUTF16String();
// (Re)set to represent UTF-16 string data
void setUTF16String(unichar *u16buf, size_t u16len, bool weak=true);
/**
* (Re)set to represent an NSString. Will make an implicit managed copy of its
* UTF-16 characters, thus owning a strong reference meaning you can let |str|
* die without messing up the life of |this|.
*/
void setNSString(NSString *str, NSRange range);
// The number of UTF-16 characters this object represents
inline size_t length() const;
// The UTF-16 characters this object represents
inline const unichar *characters() const;
// Access the UTF-16 character at index. Unchecked.
inline unichar const &operator[](size_t u16index) const;
// Maximum number of bytes needed to store a UTF-8 representation.
inline size_t maximumUTF8Size();
/**
* Convert the represented Unicode string to UTF-8, returning a (internally
* allocated) null-terminated UTF-8 C string, which will be valid as long as
* |this| is alive or until |convert| is called. You can find out the length
* of the returned string from |UTF8Length|.
*
* See |convert(uint8_t*, size_t*)| for details.
*/
const uint8_t *convert();
// Fill |str| with the UTF-8 representation
void convert(std::string &str);
/**
* Convert the represented Unicode string to UTF-8, filling |u8buf|.
*
* @param u8buf A byte buffer to be filled which must be at least
* |maximumUTF8Size| bytes long.
*
* @param u8to16_table A user-allocated lookup table which must have at least
* |maximumUTF8Size| slots. If |u8to16_table| is NULL the
* table will be created and managed internally.
*
* @returns Number of bytes written to |u8buf|
*/
size_t convert(uint8_t *u8buf, size_t *u8to16_table=NULL);
// The number of bytes used for the UTF-8 representation
inline size_t UTF8Length() const;
/**
* Return index of UTF-16 character represented by UTF-8 character at
* |u8index|. Unchecked and expects an index less than |UTF8Length|.
*/
inline size_t UTF16IndexForUTF8Index(size_t u8index);
/**
* Convert a UTF-8 range into the range of it's equivalent UTF-16 characters
* in |characters|. This has low complexity because a lookup table is
* utilized. Automatically expands to cover any pairs.
*
* @param u8range Range in UTF-8 space
* @returns valid range in UTF-16 space
*/
NSRange UTF16RangeForUTF8Range(NSRange u8range);
// Faster version of UTF16RangeForUTF8Range without checks
inline NSRange unsafeUTF16RangeForUTF8Range(NSRange u8range);
};
-
Dynamically linked at runtime since it’s licensed under the dreadful GPL ↩