Large-scale distributed processing on the web
 The title probably gives you goose bumps. No? It doesn’t? Maybe it should.
The title probably gives you goose bumps. No? It doesn’t? Maybe it should.
Imagine you have a lot of work to do, a lot of image processing work, like rescaling and cropping large amounts of pictures. Now think about the web as we know it, with web sites where people hang around for a few seconds now and then. Imagine each visitor would be given a task to complete while reading your web site. Like for instance download, rescale and crop a picture from somewhere on the web. It’s possible my friend.
Applied
For the upcoming new version of Dropular we are going to make good use of this technology.
The basic concept of Dropular can be explained with this use-case:
-
A user called kate drops a picture she just found somewhere on the web (sending its URL to the Dropular service).
-
kates dropped image appears on the Dropular front page, or in the global stream of pictures as well as appears in other places throughout dropular.net.
-
Another user — let’s call him john — visits Dropular and sees the picture dropped by kate.
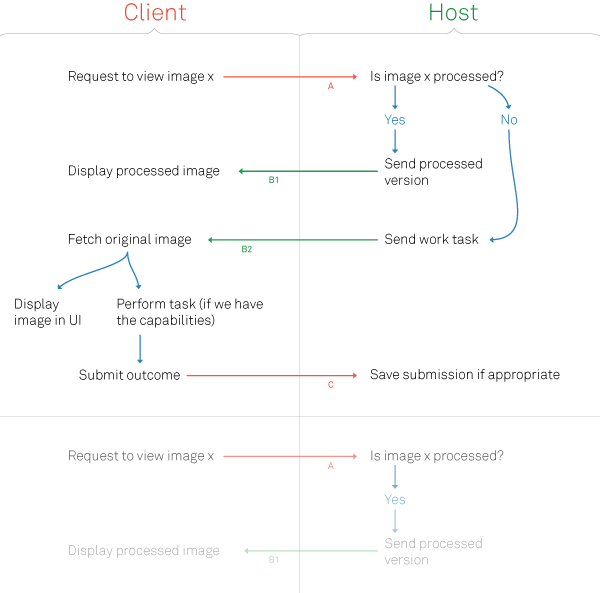
At step 3 we display a smaller version of the original image along with some metadata like a title, link to the original source, and so on. The smaller version of the image will be created by our imaginary user johns web browser. It only takes a split second and john will probably not notice anything.
Methods of processing
When it comes to image processing on the web at large, there are basically two (or three) types of methods one can employ:
- Host-based processing
- Client-based processing
- A combination of A and B
The host-based processing method has the upside of being performed in a controlled environment, thus we can assure a certain level of quality and there are few – if any – trust issues. On the other hand, processing imagery can be a very resource-intensive task requiring loads of hardware and/or time + in most cases bandwidth (sending and receiving the source and output images).
Client-based processing methods are employed by most desktop applications, but until today no web applications, basically because the technology is not yet mature enough or even available.
Moreover desktop applications in general does only perform processing on trusted data, data available in your local computer, and only uses the output of the processing itself. My Photoshop program does not email you my cropped version of crazy-cat.png – if you want to crop that picture you do it yourself.
What we are trying to do is to marry the two methods, effectively performing processing only when needed and sharing the results among visitors.
The problem with trust
So you’ve figured: the real problem with this shared distributed method is trust. What happens if a rogue user submits a bad picture? How can we trust the submitted outcome?
Ways to “work around” the trust problem:
- Only logged in users can submit.
- Race for Nth submission.
- Compare many with similarity threshold.
Method 1
Method 1 requires the submitting client to be verified (e.g. by means of username and password). The downside being a less powerful “grid” of clients performing passive processing.
A product with the majority of users being logged in, or where the logged in users are probable to activate task requests of most images, would probably benefit most from this solution.
Method 1 is probably the solution we will employ for Dropular.
Method 2
Many clients are given the same task and the Nth submission is picked. “Nth” might refer to a fixed, pre-defined number like “first response received” or “4th response received”, or it might be a random arbitrary number which changes between task contexts.
Using this method it would require a great effort from a rogue users perspective, drastically lowering the probability of success (of messing up things). However, it comes with the cost of increased latency (N number of submissions must be sent in before we can start utilising the results, i.e. a pre-processed image). It also requires more complex and foremost stateful backend (host) software.
Method 3
This method works similar to Method 2 in that we need to keep some kind of state in the host software. We request multiple submissions and compare the “outcomes” using some sort of similarity algorithm1 and identify the biggest cluster of commonality, pick one of the “outcomes” in that cluster and forget all other “outcomes”.
Here, we require a even more complex software running at the host. The upside being that rogue submissions will have a hard time making it (assuming only one submission per internet origin is allowed to participate in each session, and that the comparison algorithm is sufficient).
In practice
As of last week, my Hunch stuff – aka “box of interesting stuff” – uses this technique of distributed image processing. It currently works by using a canvas element to perform the actual processing with, then sending the resulting image data using a temporary hidden form. This currently works in Safari, Chrome and Firefox (possibly also Opera, but untested) – for sad people with Internet Explorer (or other browsers), no processing or submission will be attempted.
In the future
What more than image processing will we be able to distribute in the future? Already today we could hand out simple number-crunching tasks to clients in the same way, but what’s more alluring is the potential of distributing otherwise very expensive – or sometimes impossible – working sets. Data mining vast quantities of resources on the internet, anyone?
-
In the case of image processing, each outcome might have totally different data (bits) since most image compression algorithms (e.g. JPEG and PNG) introduce some level of randomness, thus we can not use basic data comparison like checksums. ↩